语料库检索平台
总体介绍
句法结构信息标注语料库是一类重要的语言资源,构建基于句法结构信息标注语料库的句法检索平台具有重要的实践价值。我们在词法信息的基础上融入词语的依存关系信息,引入一种轻量级的检索语言,以《国际中文教育中文水平等级标准》为词语难度控制标准,研制了检索精准、简洁方便、难度可控的文心语料库检索平台。该检索平台可广泛应用于国际中文教育、语言学本体研究、信息抽取等领域。
我们将现有研究成果集成到一个在线演示系统“文心·检索”中,欢迎大家尝试使用!
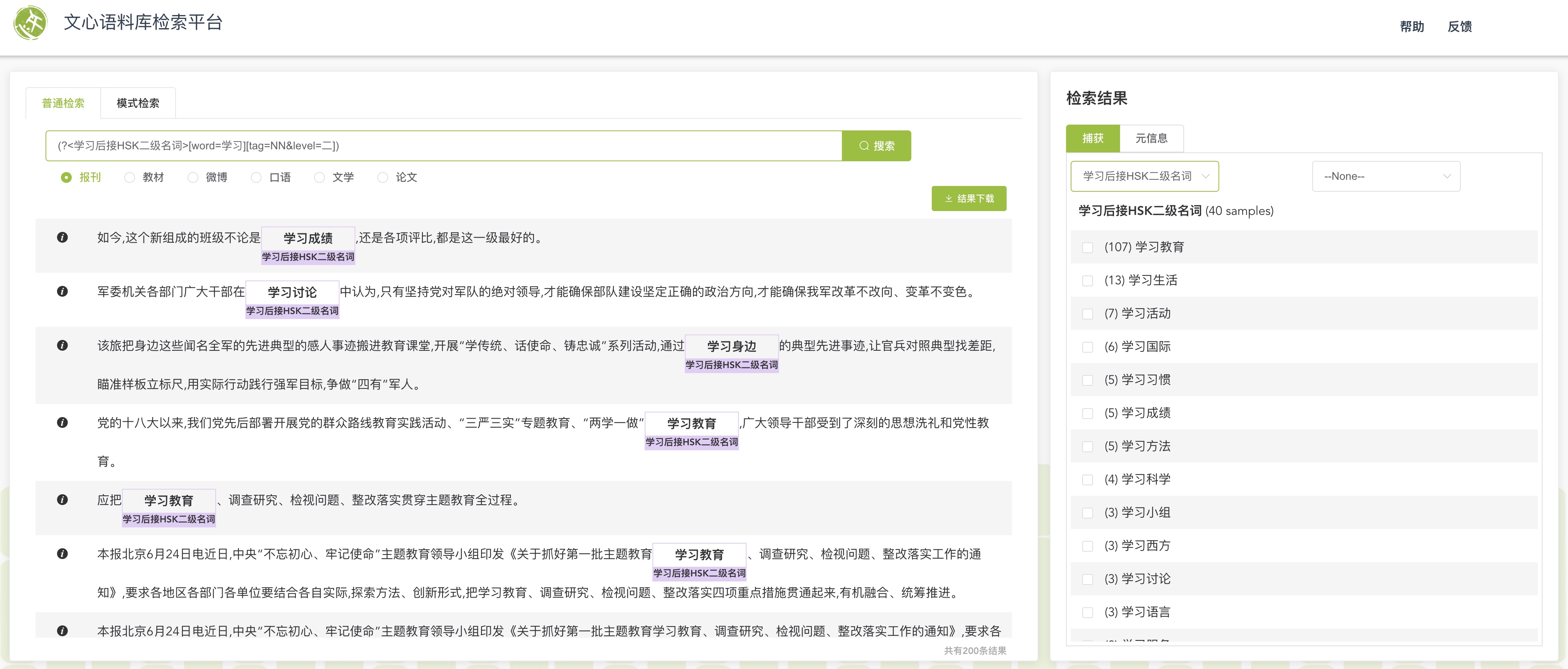
文心·检索系统:https://hunter.litmind.ink
指导老师
- 杨尔弘, 北京语言大学教授
- 杨天麟, 北京语言大学副教授
开发团队
- 朱君辉, 北京语言大学信息科学学院硕士生
- 刘 鑫, 北京语言大学信息科学学院硕士生
- 师佳璐, 北京语言大学信息科学学院硕士生(已毕业)
相关论文
语言资源建设
总体介绍
汉语学习者依存句法树库 YATLC 1.0
汉语学习者依存句法树库为非母语者语料提供依存句法分析,可以支持第二语言教学 与研究,也对面向第二语言的句法分析、语法改错等相关研究具有重要意义。我们改进依存句法标注规范,搭建了在线标注平台,对含有偏误句(汉语学习者原始语料)和目标句(纠偏后的句子)的平行句对进行标注,初步构建了汉语学习者依存句法树库,并以此探讨偏误对依存句法的影响。
汉语学习者文本多维标注数据集 YACLC 1.0
YACLC设计了一套包括最小改动、流利度提升、句子可接受度、上下文依赖性的多维度富信息标注体系,采用众包策略标注了2,421篇、32,124句的语言使用场景下的汉语学习者文本,获取到331,292个最小改动标注句和137,708个流利提升标注句。YACLC的建设既解决了汉语学习者语料库的语料来源封闭、标注结果单一和流利维度欠缺的问题,又可通过学习者语言与两个参照语变体三者之间的多元互动对比分析揭示二语习得的规律。
YACLC的建设采用众包策略。我们搭建了可供多人同时在线标注和逐句审核的众包标注平台,招募了183名汉语国际教育相关专业的标注员,分组、分阶段地进行偏误标注和审核工作。
YACLC数据集:https://github.com/blcuicall/YACLC
CCL 2022 汉语学习者文本纠错评测:https://github.com/blcuicall/CCL2022-CLTC
汉语学习者拼写检查数据集 YACSC 1.0
高级汉语水平学习者多模态口语语料库项目
国内汉语二语语料库的建设主要开始于20世纪90年代,至今已构建起若干不同类型的汉语中介语语料库,如“HSK动态作文语料库”、“留学生中介语语料库”、“外国学生汉语中介语偏误信息语料库”等。这些语料为我们研究非母语学习者汉语使用的情况提供了非常丰富的资料,但由于主要来自学习者的作文,即笔语语料,因此对我们研究非母语学习者的口语使用情况不具有针对性。目前,汉语中介语语料库建设中比较突出的问题就是书面语语料库与口语语料库发展的不平衡问题,口语语料库建设严重滞后。虽然目前也有一些口语语料库,但大多来自于学习者的课堂或考试产出,类型比较单一。我们认为学习者在真实自然状态下的互动交际中也包含了除言语信号传递以外的各类模态信息,是口语语料库区别于笔语语料库的重要特征之一,因此本项目拟从多模态的视角出发,构建针对高级汉语学习者的集音频、视频、文本于一体的多模态口语语料库,并以此为基础开展相关的应用研究。
指导老师
- 杨尔弘, 北京语言大学教授
- 岳岩, 北京语言大学副教授
- 杨天麟, 北京语言大学副教授
开发团队
- 孔存良, 北京语言大学信息科学学院博士生
- 王莹莹, 北京语言大学信息科学学院博士生
- 余婧思, 北京语言大学信息科学学院硕士生
- 袁佳欣, 北京语言大学信息科学学院硕士生
- 郭静, 北京语言大学汉语速成学院硕士生
- 时俊诗, 北京语言大学汉语速成学院硕士生
- 姚瑶, 北京语言大学汉语速成学院硕士生
- 王帼英, 北京语言大学汉语速成学院硕士生
- 田晓妍, 北京语言大学汉语速成学院硕士生
- 刘歌, 北京语言大学汉语速成学院硕士生
- 师佳璐, 北京语言大学信息科学学院硕士生(已毕业)
- 方雪至, 北京语言大学信息科学学院硕士生(已毕业)
- 罗昕宇, 北京语言大学信息科学学院硕士生(已毕业)
- 肖 丹, 北京语言大学信息科学学院硕士生(已毕业)
- 胡正升, 北京语言大学信息科学学院硕士生(已毕业)
- 彭敏, 北京语言大学汉语速成学院硕士生(已毕业)
- 魏玮, 北京语言大学汉语速成学院硕士生(已毕业)
相关论文
- Yingying Wang, Cunliang Kong, Liner Yang, Yijun Wang, Xiaorong Lu, Renfen Hu, Shan He, Zhenghao Liu, Yun Chen, Erhong Yang, Maosong Sun. YACLC: A Chinese Learner Corpus with Multidimensional Annotation. arXiv 2021 [blog] [arXiv] [data]
- 师佳璐, 罗昕宇, 杨麟儿, 肖丹, 胡正升, 王一君, 袁佳欣, 余婧思, 杨尔弘. 汉语学习者依存句法树库构建. 中文信息学报, 2022, 36(1): 39-46 [paper] [link]
众包标注
总体介绍
众包标注是利用大量个人进行数据标注的过程。 与雇用专家或专职工人相比,众包允许任务发起者以低成本、高效率的方式获取具有不同技能和能力的大量劳动力。因此,众包得到了广泛的普及,并且也成为机器学习获取训练数据的一个关键步骤。尽管众包标注具有很多优点,但其标注质量仍受到众包工人的专业知识和努力水平的限制,而这些限制对于任务发起者来说是难以衡量或遇见的。之前的工作已经提出和研究了提高收集数据质量的不同方法,包括工人选择、任务分配、异常值检测和结果聚合。我们的研究主要聚焦于其中的工人选择方法。
指导老师
- 杨尔弘, 北京语言大学教授
- 杨天麟, 北京语言大学副教授
- 黄超, 加州大学戴维斯分校博士后
- 房智轩, 清华大学交叉信息研究院助理教授
- 黄雅平, 北京交通大学计算机与信息技术学院教授
开发团队
- 王誉杰, 北京交通大学计算机与信息技术学院硕士生
- 刘洋, 北京语言大学信息科学学院硕士生
- 雷尚德, 北京语言大学信息科学学院本科生(已毕业)
相关论文
- Coming soon…