CCL 2022 汉语学习者文本纠错评测研讨会召开
2022年10月30日,汉语学习者文本纠错评测研讨会(CLTC)在南昌圆满落幕,本次会议附属于第21届中国计算语言学大会(CCL 2022),以专题研讨会的方式进行。此次评测比赛由北京语言大学联合清华大学、苏州大学、东北大学、阿里巴巴达摩院共同组织。北京语言大学语言监测与智能学习研究组(BLCU-ICALL)杨天麟副教授主持了会议。会上,博士生王莹莹作了评测总结报告,具体介绍了评测任务、技术总结、参赛队伍及获奖情况。


汉语学习者文本纠错任务(Chinese Learner Text Correction,CLTC)旨在自动检测并修改汉语学习者文本中的标点、拼写、语法、语义等错误,从而获得符合原意的正确句子。
近年来,研究者通过专家标注及众包等形式构建一定规模的训练和测试数据,在语法检查以及语法纠错等不同任务上开展技术评测。由于汉语学习者文本纠错任务相对复杂、各评测任务以及各数据集之间存在差异,因此,汇聚、开发数据集,建立基于多参考答案的评价标准,成为该领域当前需要解决的问题。本次多家单位联合推出的评测任务,整合了已有的文本纠错的相关评测数据和任务,发布了新的数据集,构建了汉语学习者文本纠错任务的基准评测框架,以设置多赛道、统一入口的方式开展比赛任务,同时开发了支持随时、长期进行评测的公共平台,旨在不断改进文本纠错数据及任务,聚焦该研究领域中的前沿问题,充分发挥评测引领技术发展、推进研究进步的作用。
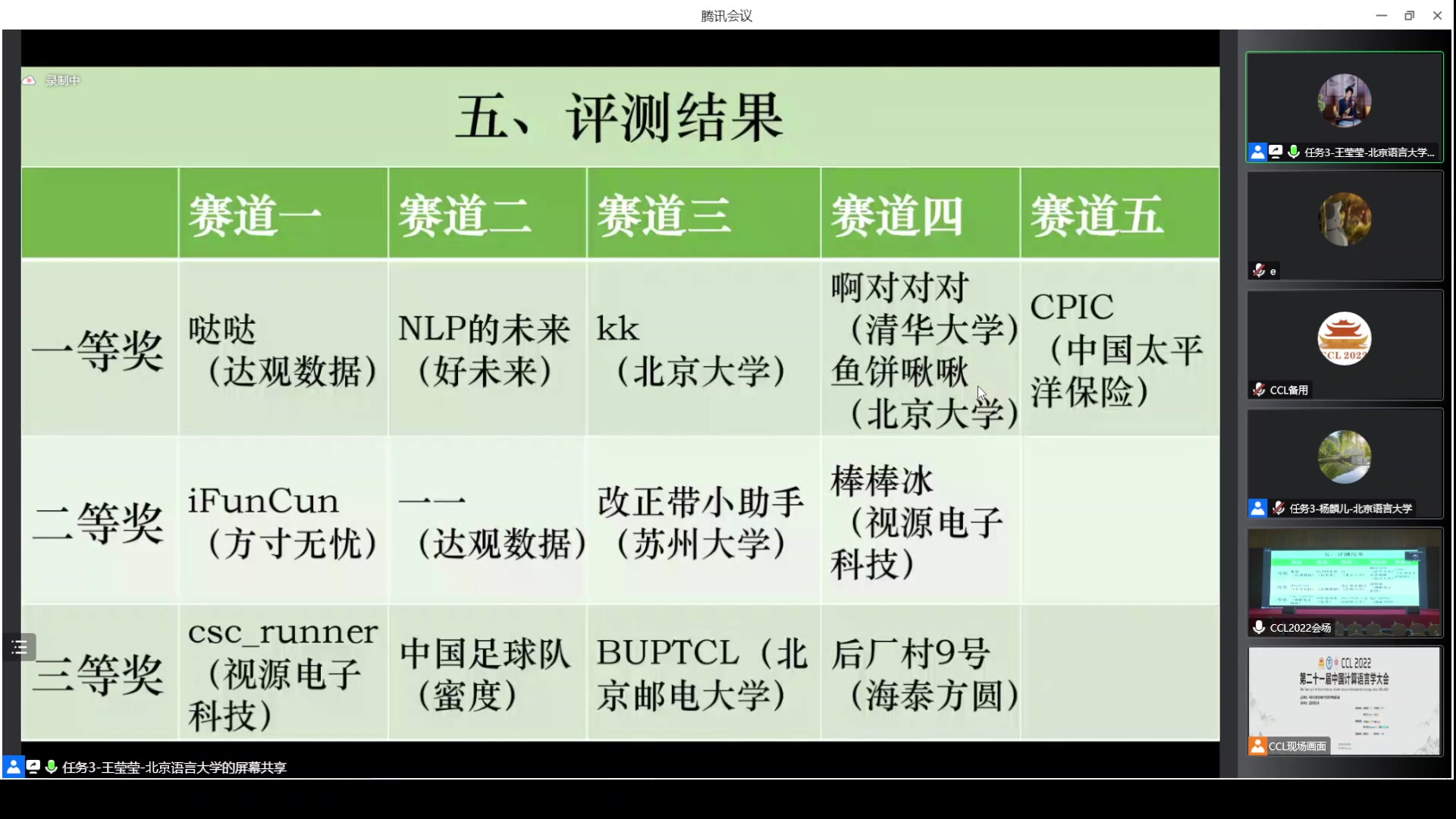
本次评测设计了五个赛道,分别设置中文拼写检查、中文语法错误检测、多维度汉语学习者文本纠错、多参考多来源汉语学习者文本纠错、语法纠错质量评估。五个赛道共有142支队伍报名,包括清华、北大、中科院、北邮、苏大等高校和科研院所,达观、蜜度、好未来、视源等企业。各赛道的获奖队伍代表在评测研讨会上做了技术报告,相较于基线模型,参赛系统的性能有大幅提升,展现出了汉语学习者文本纠错任务上的现有水平,与会者进行了充分的讨论。

此次评测任务将由语言监测与智能学习实验室(BLCU-ICALL)汇聚成综述报告,与获奖队伍评测报告一起公开在本网站评测报告页面。
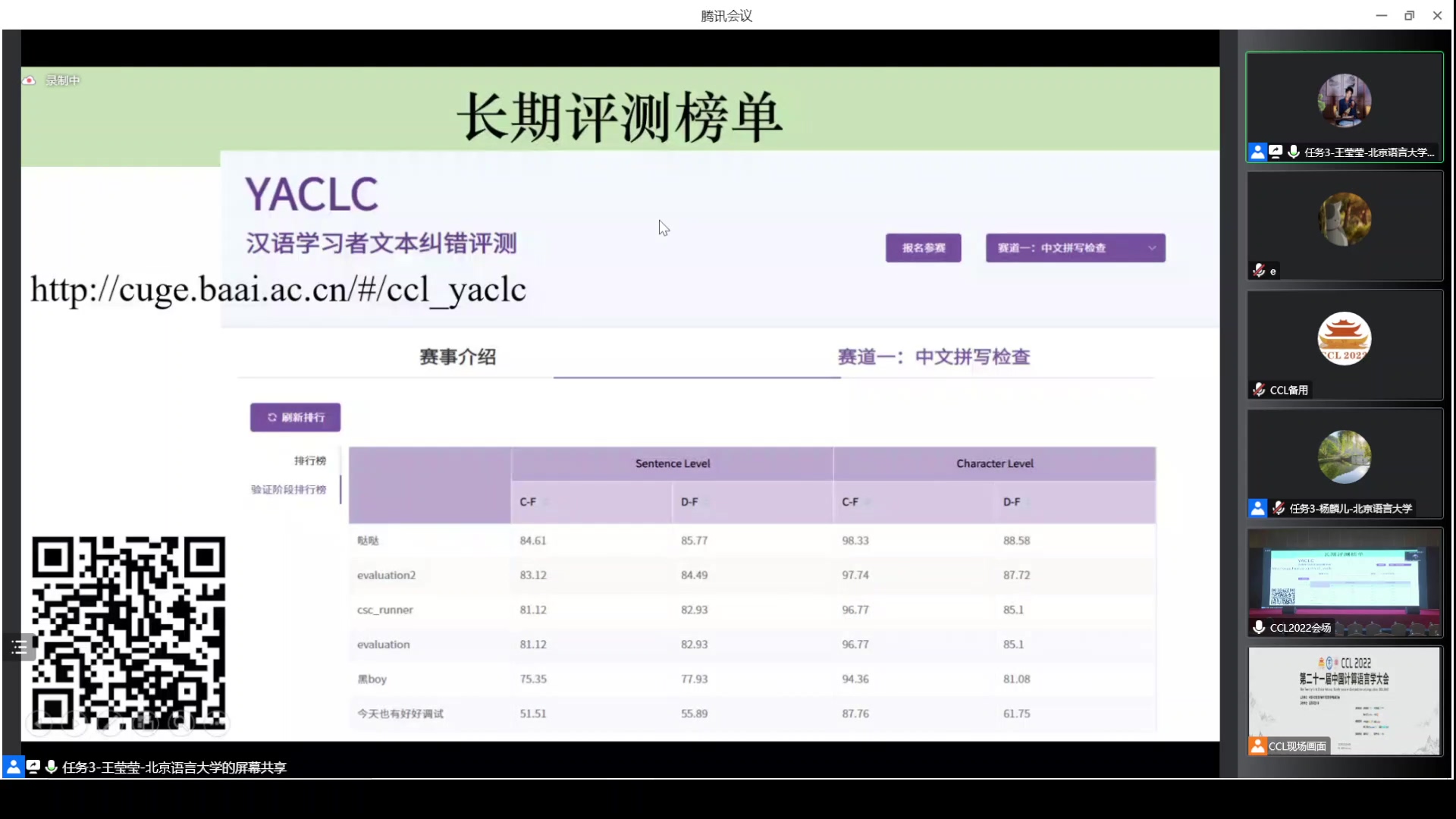
同时,为了供研究者继续参与评测,智源指数平台提供了长期的评测榜单,以进一步推动汉语学习者文本纠错研究的发展。
中国计算语言学大会创办于1991年,是中国中文信息学会(CIPS)的旗舰会议。经过近三十年的发展,CCL已经成为国内自然语言处理研究领域最具影响力的学术交流平台。CCL从2017年开始组织技术评测,为中文语言处理研究者提供测试相关技术、算法和系统的平台。现已组织评测任务19项,涉及自然语言处理研究与应用的多个方面,开放了多个公开数据集,参赛队伍累计达数千支,呈现出评测推动技术发展的聚合效应。