发布 | 汉语学习者语料库标注平台
导言
学习者语料库(Learner Corpus)是外语/第二语言学习者产生的真实文本的集合。它不仅可以用于第二语言习得研究,还可以识别特定学习者群体(例如中级学习者)在学习中的典型困难,从而为识别学习者语言中经常发生的错误提供帮助。
汉语学习者语料库标注平台

汉语学习者语料库标注平台是由北京语言大学语言监测与智能学习研究小组研发的,其目的是对汉语学习者语料进行偏误标注,建构语料库。汉语学习者语料库立足于智能计算机辅助语言学习,构建完成后,将在对外汉语教学研究、汉语学习者的语言能力研究、中介语系统研究、偏误分析等研究领域发挥作用。
截至目前,我们招募到了142名偏误标注人员,已标注了的语料总和为:2,326篇文章,31,451个句子,546,572个字。
偏误标注体系的建立
偏误类型界定
偏误是指“中介语与目的语规律之间的差距” (鲁健骥,1984)。比如,某位汉语学习者在遇到心仪的对象时,忍不住向对方表白,却说道“我你喜欢!”这就让人听得一头雾水了。但其实这种情况是有些汉语学习者(日韩居多)在学习汉语过程中由于受到母语影响而出现的一种偏误情况。
从语法学上来进行划分的话,汉语学习者在使用汉语过程中产生的偏误,既有字、词、短语、修辞、标点符号、语篇等层面偏误,也有语义、语用以及语体等层面的偏误;在不同的层面,偏误的数量分布也各不相同。鲁健骥认为,“对外汉语教学的语法项目大致可以分为两大类,一类是词语的使用,也包括各种词类的使用,尤其是副词、连词、助词等虚词的使用,也包括各种短语(如介宾短语)、结构等的使用。另一类是句法项目,包括各种句子形式(在对外汉语语法教学中则主要表现为句型的教学)。这两大类语法项目都会有遗漏、误加、误代、错序的偏误,所不同的是,前者是与词语的意义、用法有关的偏误;后者是由词语充当句子成分使用上的偏误。”结合鲁健骥的观点及自然语言处理的相关特点,我们将本语料库中的偏误类型界定为成分缺失、成分冗余、语序错误、词汇混用四类。这种偏误分类降低了标注员进行偏误标注的难度,并且有利于后期的语言模型进行特征学习。
标注原则
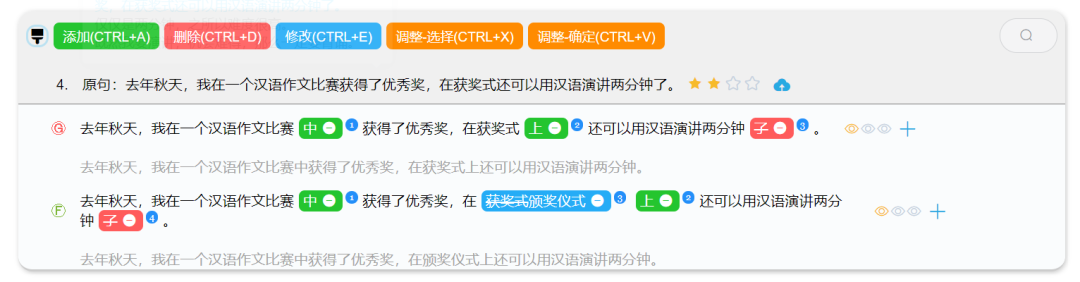
我们的标注原则分为基本原则和特殊原则。基本原则包括:
(1)词的粒度:本语料库标注粒度为“词”,即要在词层面上进行标注的相关操作。
(2)最小改动:在进行偏误标注修改时,尽量用最少的改动来完成对句子的修改。
(3)忠于原意:修改时要结合(2)来进行修改,尽量少改,遵循作者原意。
特殊原则包含纠偏原则和流利原则,具体如下:
(1)纠偏原则(G)
G 即纠偏 (grammar edit),纠偏要求纠正原句中的偏误。原则上要求每个句子标注 1 条基于纠偏原则的修改结果。
(2)流利原则(F)
F 即流利 (fluency edit),不仅要求将句子修改正确,还要修改得更为流利和地道。所谓流利,即句子表达是否自然流畅,是否符合汉语的表达习惯;如果一个句子出现了语法错误,则默认为该句不够流利。
此外,我们还提出了基于句意、语法、流利三个维度的星级标注指标,对句子的可接受度进行评判。
综上,基于汉语学习者语料库标注平台,我们的标注任务是:
给出原句的可接受度,在符合原意以及尽可能保持原句的语言结构和成分的基础上,纠偏(G)和流利(F)各给出1-2条正确的标注结果,并将两种类型的标注区分出来。