新闻 | 国家语言资源动态流通语料库DCC 2.0发布
文心语料库检索平台
2022年11月19日,第十二届全国语言文字应用学术研讨会暨《语言文字应用》创刊三十周年学术研讨会召开。研讨会上,硕士生朱君辉代表北京语言大学BLCU-ICALL研究团队进行了分组汇报,公开发布文心语料库检索平台。

研究团队在DCC 1.0动态流通语料库的基础上对语料资源进行了扩充,推出了DCC 2.0语料库,并结合前沿语料库检索技术,打造出文心语料库检索平台。由于DCC 2.0语料库的支持,文心语料库检索平台具有全领域、多覆盖的语料资源,原始语料经过深加工与多级标注,其强大的检索功能不仅支持远距离、深层次的句法结构的检索需求,不同的检索模式还能够同时兼顾检索功能的全面性与用户友好性。
全领域、多覆盖的语料资源:
除了沿袭DCC 1.0的新闻语料之外,DCC 2.0语料库还将500多册市面上广泛使用的国际汉语教材语料收录其中,以便于国际中文教育领域的教师、研究人员的使用。语料具有丰富的元信息,如所在文档ID、所在文档标题、所在文档来源、所在文档日期等。
文学、微博、口语、学术论文等领域语料也将陆续上线。

语料经过深加工与多级标注:
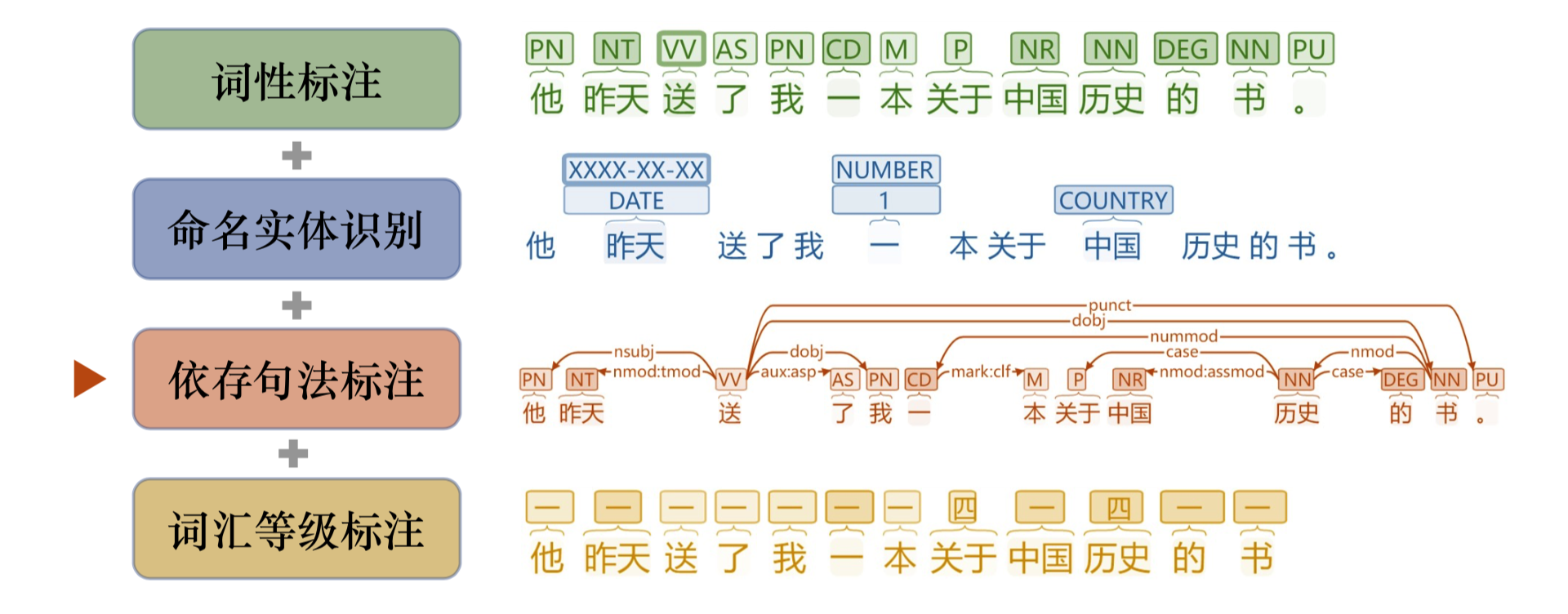
不同于DCC 1.0, DCC 2.0中的原始语料进行了分词、词性标注、命名实体识别、依存句法关系、词语难度等级的语料深加工及多级标注。其中,词语难度等级参照了国家语委2021年4月新发布的《国际中文教育中文水平等级标准》(GF0025-2021)中的“5 汉字表”与“6 词汇表”,在此基础上做了部分词汇的难度类推。依存句法标注则分为两个层面,一是基于SD(Stanford Dependency)规范的普通依存句法标注,二是基于BLCU-ICALL研究团队对SD依存规范进行改进的加强依存句法规范,进行了加强依存句法标注。(参考文献:余婧思等. 汉语增强依存句法自动转换研究. 第二十一届中国计算语言学大会 (CCL 2022))
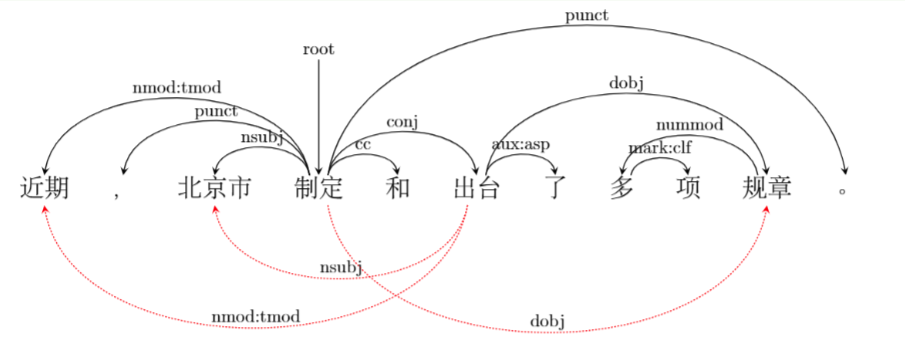
有了原始语料深加工的支撑,依托于文心语料库检索平台,用户不仅可以对字和词进行检索,还可以通过词性、命名实体、依存关系、词语难度等级对检索词进行约束检索。
强大的检索功能:
文心语料库检索平台采用一种前沿的语料库检索技术,定义了一种用户友好且功能强大的语料库检索语句,同时支持基于词的检索与句法语义检索,旨在提供高度准确的检索结果的同时,保持检索语言的简洁性。
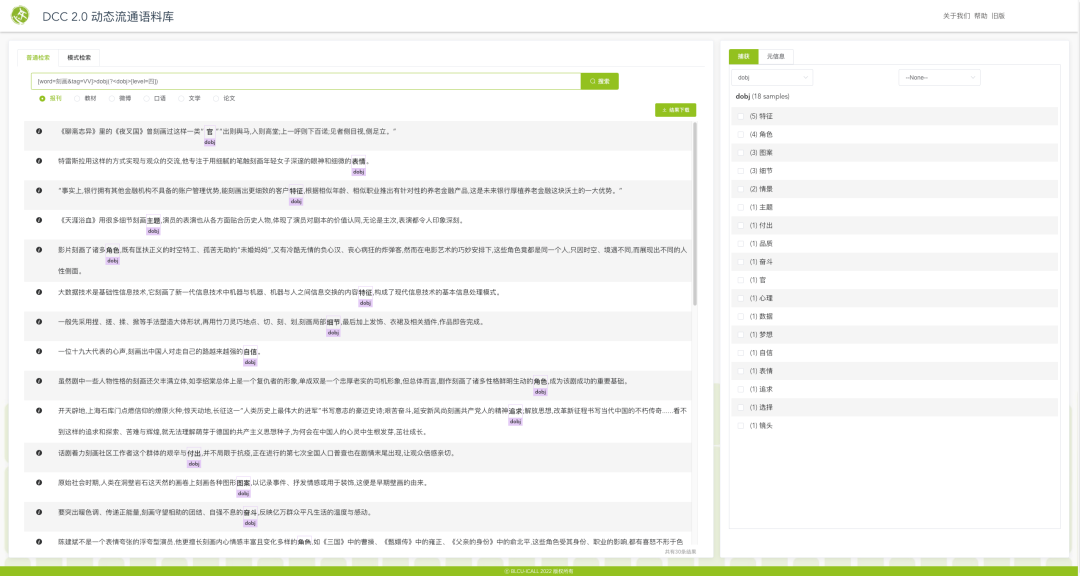
文心语料库检索平台支持两种检索模式。“普通检索”用于检索单个语言单位以及有顺序和间隔规定的多个语言单位。全局支持使用正则表达式,支持复杂的检索表达式查询(如依存句法、命名实体、词汇难度查询等),支持按出现频次对规定的捕获内容进行统计。(检索表达式的具体构成及检索方式可登录平台,参考“使用帮助”模块的帮助手册。)
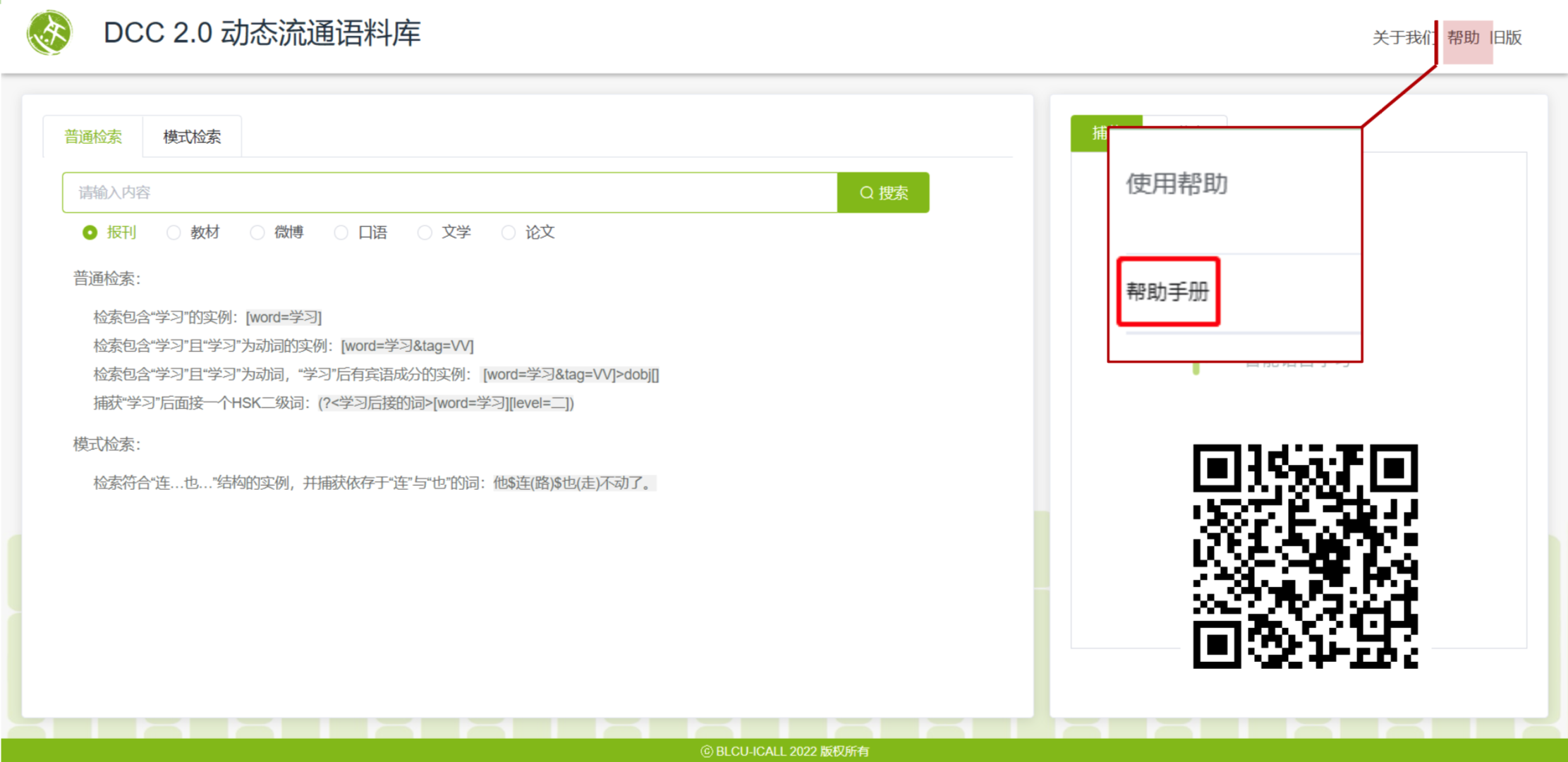
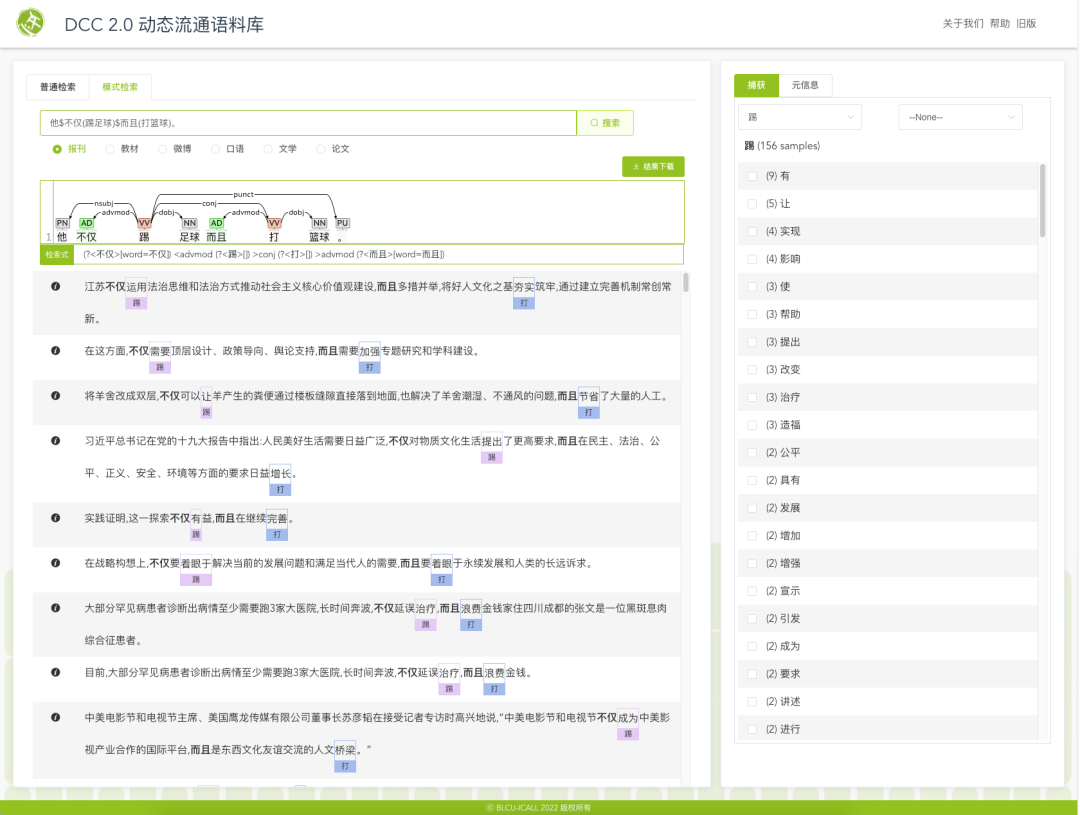
复杂的检索式虽然可以精准匹配,但需要用户熟记诸多底层的语法标签。而通过“模式检索”,使用者不需学习检索语言,通过给出包含关键词/成分的例句进行模式匹配即可检索。“模式检索”的检索方式更为友好,使用者只需使用“锚点$”与“捕获()”两种符号,通过给定例句,检索出与例句的句法结构一致的句子。这种方式使得使用者无需花费更多的时间记忆检索符号,可大大提升检索的效率。
文心语料库检索平台支持元信息的查询和过滤,辅助用户在检索结果的基础上进行再检索。

DCC 2.0语料库的应用前景
文心语料库检索平台作为DCC 2.0语料库和强大的语料库检索技术的高度集成体,一方面可以为语言学本体研究提供大规模、多领域的语料,另一方面可以在辅助教学和丰富教学资源方面起到一定成效,在语言教学领域具有实际的应用价值。
如用来辅助语法点教学及搭配学习,其检索功能可以提高教师备课质量与效率,为教材或试卷编写提供丰富的用例。第一,通过依存句法来进行检索,即使是面对比较复杂的语法点或是包含距离较远的句法成分的语法点,也能够得到比较准确的结果;第二,在检索时可以对词汇难度等级进行限制,帮助教师在检索时能充分考虑学生的汉语水平,检索到适合不同学生的例句,提高检索的针对性;第三,捕获功能方便教师查看句中的不定成分,能帮助教师更容易地查看词汇间的搭配和聚类关系。
此外,文心语料库检索平台还适用于构式研究,大规模语料为研究构式提供了基础,该语料库可以按照依存句法来检索,给出了句法上的关系,即使构式各项之间距离较远,也能够得到比较好的检索结果。
结语
文心语料库检索平台有着现实的应用价值与广阔的应用前景。其中,丰富的语料领域、语料的深加工及多层标注、强大且简洁的语料库检索模式,为知识抽取、语言研究和应用工作提供便利。其研究成果可广泛应用于对外汉语教学、汉语二语习得、汉语学习者词典编撰等领域,有助于语言学本体精细化研究与国际中文教育领域的教学与习得。
DCC语料库简介
国家语言资源动态流通语料库(Dynamic Circulation Corpus,DCC)由张普教授创立,现由北京语言大学国家语言监测与研究平面媒体中心(http://cnlr.blcu.edu.cn)维护管理。该语料库采样全国100多份报纸,涵盖中国各省市,每年递增20多亿字次。DCC语料库具有历时、动态更新、实态记录等特点,可提供词语的历时使用分布数据,是语言生活研究、服务与应用的历时大数据。
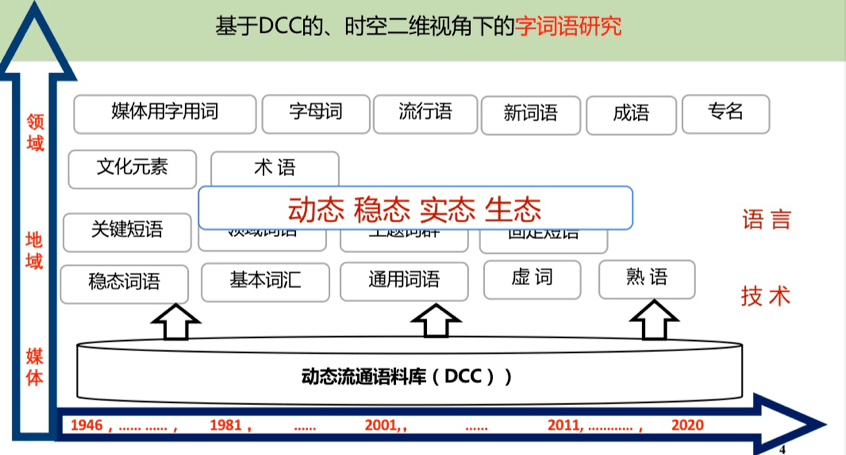
DCC语料库以监测、描述语言现象,发现、提取并动态更新语言知识为目的,其核心理念在于与时俱进、动态更新,通过随时关注社会生活和语言运用的变化情况,为人们从历时和共时角度把握语言发展变化的规律提供理论和实践上的支持。下图展示了DCC语料库的检索平台界面。
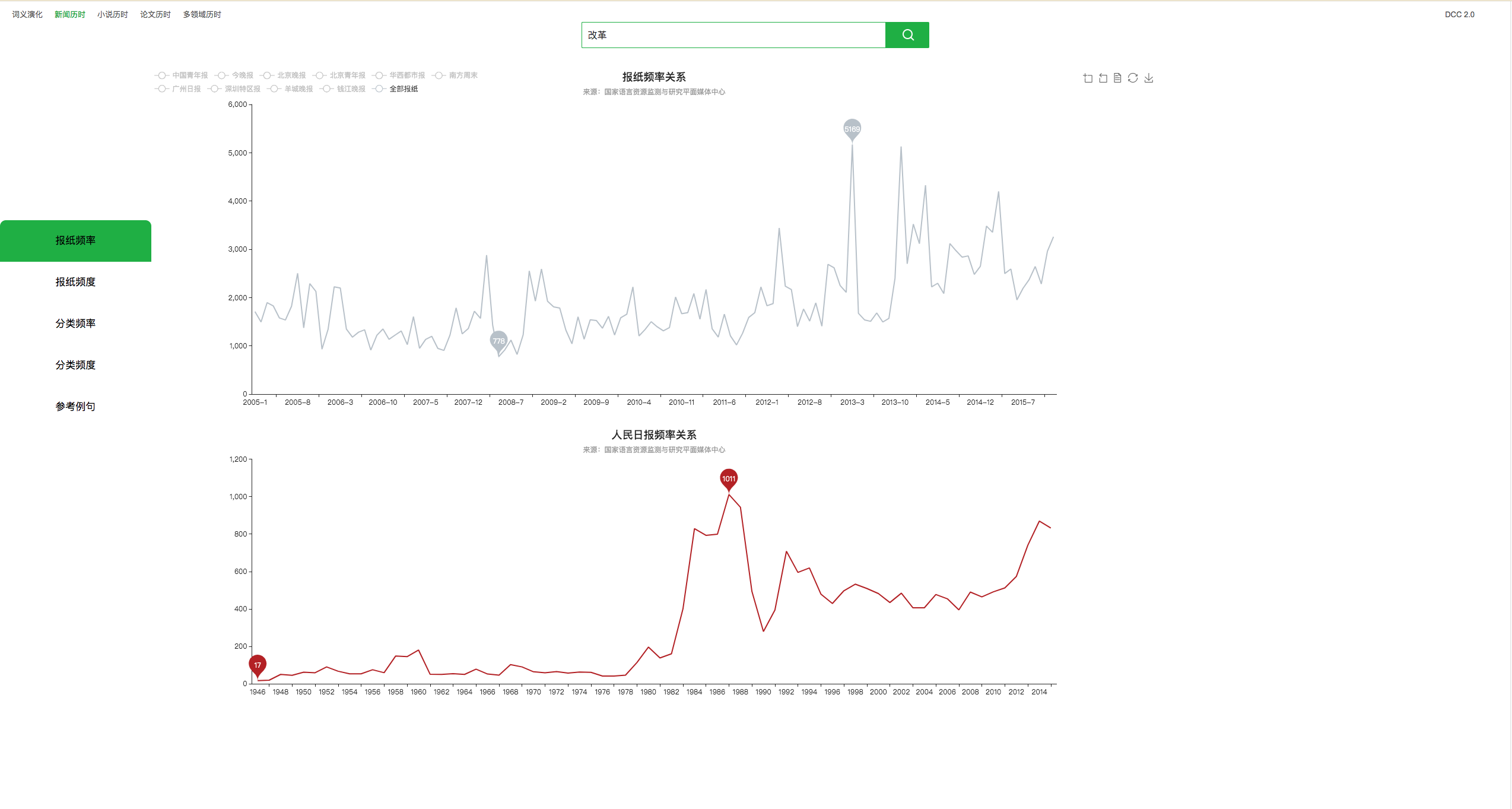
基于DCC语料库开展了语言检测的许多工作,主要研究内容包括对媒体通用词语、年度媒体用字用语、新词语、流行语、固定短语、命名实体、主题词群等汉语字、词、语等层面的使用实态进行考察与分析,相关研究成果每年被收录到《中国语言生活状况报告》中,定期向社会公布。此外,DCC语料库还支持了《通用规范汉字表》和《汉语国际教育用音节汉字词汇等级划分》的研制。下图展示了时空二维视角下的基于DCC语料库的汉语字词语研究。