新闻 | 杨尔弘:基于语言数据的智能辅助学习初探

12月12日晚,北京语言大学杨尔弘教授于“全球中文教学线上交流平台(第十一场):基于语料库/数据库的国际中文教学与研究”研讨活动上做学术报告。报告题目为:基于语言数据的智能辅助学习初探。报告中,杨尔弘教授介绍了动态流通语料库(DCC),并重点介绍了我组近期面向智能辅助学习开展的相关研究工作。
动态流通语料库
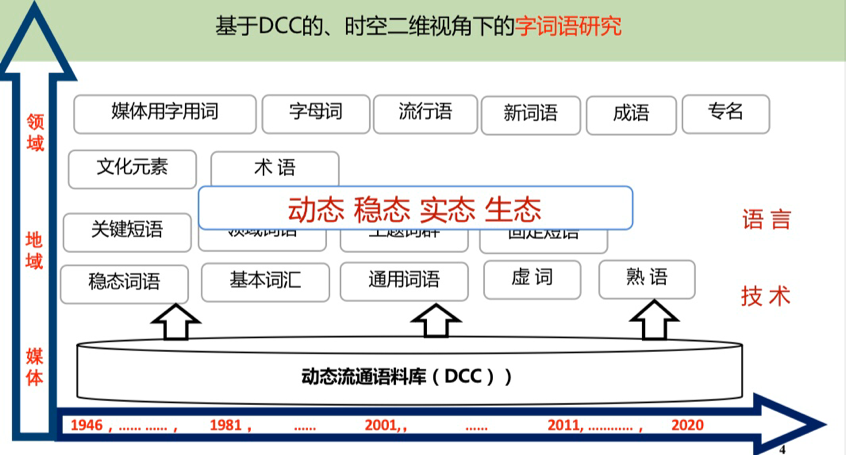
动态流通语料库(DCC)由张普教授创立,现由北京语言大学国家语言监测与研究(平面媒体)中心维护管理。该语料库采样全国100多份报纸,涵盖中国各省市,每年递增20多亿字次。DCC语料库具有历时、动态更新、实态记录等特点,可提供任意词语的历时使用分布数据,是语言生活研究、服务与应用的历时大数据。此外,DCC语料库还支持了《通用规范汉字表》和《汉语国际教育用音节汉字词汇等级划分》的研制。在报告中,杨尔弘教授以图表的形式展示了时空二维视角下的字词语研究。
智能辅助学习

近期,我组基于语言数据,面向智能辅助学习(Intelligent Computer-Assisted Language Learning, ICALL)开展了一系列探索研究。在报告中,杨尔弘教授重点介绍了“文心”汉语学习者语料库、“文心”作文辅助写作、“文心”词典辅助编纂等工作。




“文心”汉语学习者语料库
“文心”汉语学习者语料库(YACLC)是一个大规模多标注语料库,主要收集、加工汉语学习者在使用第二语言进行交流时说或写的语言。
有以下三个主要特点:
-
数据来源多样:YACLC的数据来源包括了网络、各大高校、HSK考试等,从多角度反映出真实的汉语学习者语言状况;
-
标注形式丰富:语料库不仅标注学习者在语言使用中产生的偏误,也进行了依存句法标注和语义标注(处理加工时以句为单位)等;
-
加工方式独特:在处理加工时,采取众包的方式,对语料进行多人标注,同时对标注的质量加以控制。


目前,“文心”汉语学习者语料库已经为CGED 2020(中文语法偏误检测比赛)提供了数据支撑,并拟在CCL 2021(中国计算语言学大会)上举办语法偏误修正、二语分词及词性标注、二语依存句法分析、语义角色分析等技术测评。
“文心”作文辅助写作
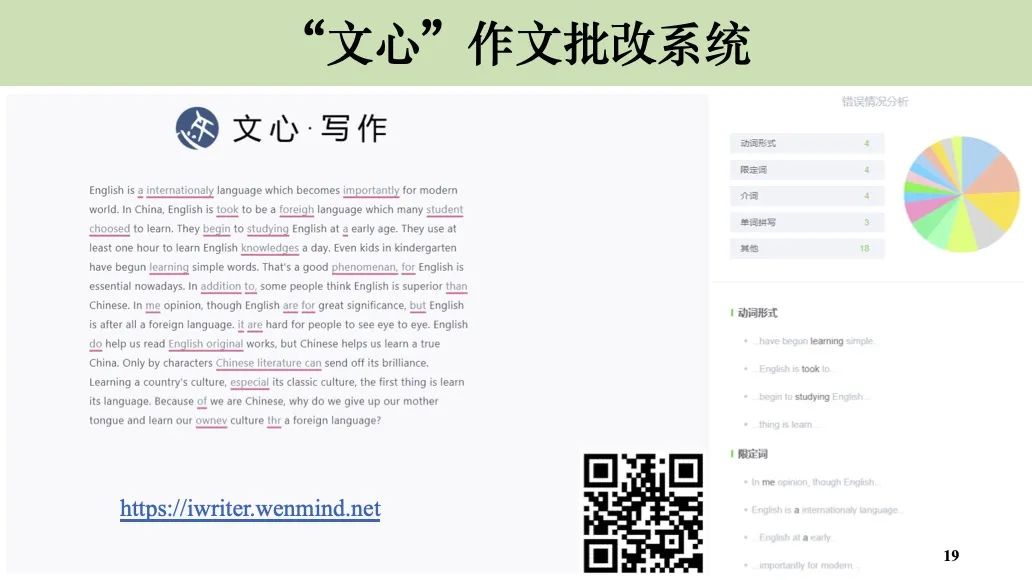
“文心”作文辅助写作的核心技术为自动语法改错(Grammatical Error Correction),旨在借助计算机,自动将存在语法偏误的句子修改为语法正确的句子,以帮助汉语学习者提升汉语能力,并且减轻汉语教师的作业批改负担。目前,“文心·写作”系统均已上线,欢迎点击文末链接试用。

“文心”词典辅助编纂
“文心”词典辅助编纂的核心技术为释义自动生成,可以为给定的词语和上下文,使用计算机自动生成该词语在当前上下文中的释义。该技术可以为未被词典收录的新词语自动生成释义,也可以生成词语在特定语境下的释义。“文心·词典”也已经上线,欢迎大家试用。

相关系统链接(目前只支持电脑端):
文心·写作(英文):https://iwriter.wenmind.net
文心·写作(中文):https://writer.wenmind.net
文心·词典 :https://dictionary.wenmind.net
以上系统均处于开发阶段,如有疑问,请关注公众号后在后台留言提问。
相关发表论文:
- 肖丹等. 汉语中介语的依存句法标注规范及标注实践. 中文信息学报. 2020.
- 师佳璐等. 汉语学习者依存句法树库构建. 第十九届中国计算语言学大会. 2020.
- 王辰成等. 基于Transformer增强架构的中文语法纠错方法. 中文信息学报. 2020.
- 张海同等. 基于门控化上下文感知网络的词语释义生成方法. 中文信息学报. 2020.
- 范齐楠等. 基于BERT与柱搜索的中文释义生成. 第十九届中国计算语言学大会. 2020.
- 张生盛等. 面向汉语作为第二语言学习的个性化语法纠错. 第十九届中国计算语言学大会. 2020.
- Yang et al. Incorporating Sememes into Chinese Definition Modeling. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2020.
- Yang et al. Controllable Data Synthesis Method for Grammatical Error Correction. Frontiers of Computer Science. 2021.
- Kong et al. Toward Cross-Lingual Definition Generation for Language Learners. arXiv 2020.