新闻 | CCL 2022 中文语法纠错评测

中文语法纠错任务(Chinese Grammatical Error Correction,CGEC)旨在自动检测并修改中文文本中的标点、拼写、语法、语义等错误,从而获得符合原意的正确句子。近年来,中文语法纠错任务越来越受到关注,也出现了一些有潜在商业价值的应用。为了推动这项研究的发展,研究者通过专家标注以及众包等形式构建一定规模的训练和测试数据,在语法检查以及语法纠错等不同任务上开展技术评测。同时,由于中文语法纠错任务相对复杂、各评测任务以及各数据集之间存在差异,在一定程度上限制了语法纠错的发展。因此,我们希望通过汇聚、开发数据集、建立基于多参考答案的评价标准、进一步完善语法纠错数据以及任务的建立,聚焦该研究领域中的前沿问题,进一步推动中文语法纠错研究发展。
我们依托第二十一届中国计算语言学大会(CCL 2022),组织中文语法纠错评测。本次评测既整合了已有的相关评测数据和任务,又有新开发的数据集,以设置多赛道、统一入口的方式开展比赛任务,同时,我们研制了各赛道具有可比性的评测指标,立足于构建中文语法纠错任务的基准评测框架。

评测任务更详细内容可查看评测网站:
https://github.com/blcuicall/CCL2022-CGEC
遇到任何问题请发邮件或者在 Issue 中提问,欢迎大家参与。
1、任务内容
本次评测设置以下四个赛道:
赛道一:中文拼写检查(Chinese Spelling Check)任务目的是检测并纠正中文文本中的拼写错误(Spelling Errors)。对于给定的一段输入文本,最终需给出拼写错误的位置及对应的修改结果,其中拼写错误包含:音近、形近、形音兼近三种。如表1所示,“14”“15”为两个错误位置,“印”“象”为对应位置的修改结果。如该句没有错误,则输出“(id=xxx) 0”即可。

赛道二:中文语法错误检测(Chinese Grammatical Error Diagnosis)任务目的是检测出中文文本中每一处语法错误的位置、类型。语法错误的类型分为赘余(Redundant Words,R)、遗漏(Missing Words,M)、误用(Word Selection,S)、错序(Word Ordering Errors,W)四类。针对M和S类错误,给出纠正结果。如表2中所示,原句的第一个错误是位置为第6到7的词“了解”,错误类型为R,即误用;第二个错误是位置为8的词“这”,错误类型为R,即赘余。

赛道三:多参考中文语法纠错(Multi-reference Chinese Grammatical Error Correction)。同一个语法错误从不同语法点的角度可被划定为不同的性质和类型[1],也会因语言使用的场景不同、具体需求不同,存在多种正确的修改方案。赛道三的数据中提供针对一个句子的多个参考答案,并且从最小改动(Minimal Edit,M)和流利提升(Fluency Edit,F)两个维度对模型结果进行评测。最小改动维度要求尽可能好地维持原句的结构,尽可能少地增删、替换句中的词语,使句子符合汉语语法规则;流利提升维度则进一步要求将句子修改得更为流利和地道,符合汉语母语者的表达习惯。如表3中所示,原句在两个维度均有多个语法纠错的参考答案。

赛道四:语法纠错质量评估(Quality Estimation),是评价语法纠错模型修改结果质量的方法[2]。如表4所示,该方法通过预测每一个语法纠错结果的质量评估分数(QE Score)来对语法纠错的结果进行质量评估,以期望对冗余修改、错误修改以及欠修改情况进行评估。该分数可以通过句子级别和词级别的质量评估分数得到[3],可以对语法纠错系统生成的多个纠错结果进行重新排序,以期望进一步提升语法纠错效果。

注:其中红字表示替换字符,蓝字表示插入字符,删除线表示删除字符。
2、评测数据
本次评测不提供官方训练数据集
赛道一的参赛队伍可使用现有的真实开源数据集进行训练,如SIGHAN 2013[4]、CLP 2014[5]、SIGHAN 2015[6]等。也可以使用伪造数据集,如Wang提供的27.1K数据集[7]。此外,SIGHAN历年赛事中也给出了音近、形近混淆集(Confusion Set)作为参考,选手可按需使用。
赛道二的参赛队伍可自行使用前七届CGED评测任务中提供的训练集、测试集和所有外源性数据资源。
赛道三和赛道四的参赛队伍可自行下载NLPCC2018-GEC[8]发布的采集自Lang8平台的训练数据,也可使用其他公开的人工标注数据集和伪造数据集。但请务必先使用我们提供的数据剔除程序对所使用的所有训练数据进行过滤,以保证训练集与开发集、测试集无重合数据。
本次评测针对每个赛道提供评测数据集,包括供参赛队伍进行模型调优的开发集,以及评测参赛队伍的模型性能的封闭测试数据集。数据来源为汉语学习者文本多维标注数据集YACLC[9]和中文语法纠错数据集MuCGEC[10]。YACLC[9]是一个大规模、高质量、篇章级别、多维度、多参考的中文语法纠错数据集。标注实践中采用众包策略,在搭建的可供多人同时使用的在线标注平台上分组、分任务、分阶段地进行标注和审核工作。MuCGEC [10]是一个多参考答案、多领域的中文语法纠错数据集,采用了基于流利度的直接改写标注方式。
下面分别描述每个赛道提供的评测数据集具体情况:
赛道一提供YACLC-CSC数据集。在拼写错误标注方面,YACLC-CSC继承前人的研究,规定只标注和修正“音近”和“形近”有关的错误。判定为“音近”或“形近”或“形音兼近”的依据来自相关的汉语语音学、文字学理论及对外汉语教学理论。标注过程采用多人标注再由专家审核的方式以保证标注质量。
赛道二提供CGED-8数据集。数据来源为HSK动态作文语料库[11]和全球汉语中介语语料库[12]。CGED-8共包括约1400个段落单元、3,000个错误。每个单元包含1-5个句子,每个句子都被标注了语法错误的位置、类型和修改结果。
赛道三提供最小改动和流利提升两个维度的三个多参考数据集YACLC-Minimal、YACLC-Fluency和MuCGEC。
赛道四提供的评测数据集基于赛道三提供的YACLC-Minimal和YACLC-Fluency进行构建,数据划分与赛道三相同。我们基于BART-large训练了基于Seq2seq结构的语法纠错模型。并将改语法纠错模型在柱搜索解码过程中排名前五的生成结果作为待进行质量评估的语法纠错候选方案,以此构建语法纠错质量评估的训练集、验证集以及测试集。同时评测数据给出了训练集和验证集中每个语法纠错方案的真实_F0.5_分值。
本次评测在模型训练方面的具体规则如下:
1 ) 所有赛道用于训练的数据必须可以开源获取,并应在论文中说明或以其他方式向比赛组织方公开,不得使用闭源及私有数据。
2) 所有赛道用于训练的数据必须先使用我们提供的数据剔除程序处理,以防止训练集与开发集、测试集重合。不遵守规定导致结果不可复现的,将取消比赛资格并删除已产生的比赛结果。
3) 赛道四要求语法纠错结果重排序过程中只能对所提供的语法纠错候选进行重排序,不得混合其他语法纠错模型所提供的语法纠错结果。
4) 不允许将开发集加入到训练数据中。开发集数据只可以用来调参和选择模型。
5) 我们可能会根据大家的反馈,进一步明确或完善规则,请大家关注。如果有不明确的地方,务必和我们联系。
6) 不允许任何队伍以开小号的形式刷榜。
3、评价标准
本次评测4个赛道的测试数据集采用封闭方式给出,即仅给定输入文本,需要参赛队伍进行推理预测,并将结果文件打包上传至在线评测平台。平台随后会给出相应赛道的指标得分。每支队伍每天仅可提交3次测试集结果。
3.1 赛道一:中文拼写检查
赛道一所需的结果文件格式见表1的任务示例。文件每行是对应一个原句的校对结果,每行内容为原句的id,错误位置及纠正结果。所使用的评测指标分为两种:一种是句级(Sentence Level),即一句输入文本中所有错别字都检测或纠正正确,则算作正确;一种是字级(Character Level),即不考虑当前句的限制,最终的评价是基于整个测试集所有汉字的错误检测或纠正结果确定。对每个级别来说,又分为错误检测(Error Detection)和错误纠正(Error Correction)两个维度。错误检测评估的是错误位置的侦测效果,错误纠正评估的是对应位置错误修正的效果。对于每个维度的评测,我们统一使用准确率(Precision)、召回率(Recall)和F1作为评价指标。
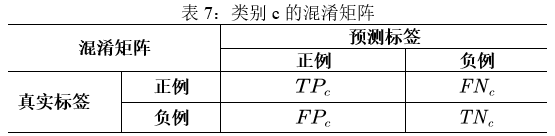
\[P_c = \frac{TP_c}{TP_c + FP_c}\] \[R_c = \frac{TP_c}{TP_c + FN_c}\] \[F_c = \frac{2 \times P_c \times R_c}{P_c + R_c}\]其中,TP(真正例,True Positive)、FN(假负例,False Negative)、FP(假正例,False Positive)、TN(真负例,True Negative)之间的关系可以用以下混淆矩阵(Confusion Matrix)来表示:
3.2 赛道二:中文语法错误检测
赛道二所需的结果文件格式见表2的任务示例。文件每行是对应一个原句的一处检测结果,每行内容为原句的id、错误位置、错误类型及纠正结果。从下述五个方面以精确率、召回率和F1值对系统性能进行评价:
1) 假阳性(False Positive):正确段落单元被判包含错误的比例。
2) 侦测层(Detective-level):对段落单元是否包含错误做二分判断。
3) 识别层(Identification-level):本层子任务为多分类问题,即给出错误点的错误类型。
4) 定位层(Position-level):对错误点的位置和覆盖范围进行判断。错误的边界以词边界界定,分词颗粒度参考jieba缺省模式。
5) 修正层(Correction-level):参赛系统被要求提交针对错误字符串(S)和字符串缺失(M)两种错误类型的修正答案。每赛题的S和M型错误,均提供1-3个正确答案。参赛队伍可提供1-3个修正结果。精确率和召回率的分子为正规测试集中被命中的答案数量。
3.3 赛道三:多参考中文语法纠错
赛道三所需的结果文件格式是每行对应一个原句的纠正结果。且每个原句仅需提供一个结果。采用的评测指标为基于字的编辑级别的\(F_{0.5}\)指标。其具体计算步骤如下所示:
1) 我们首先使用基于字的编辑抽取工具抽取出预测编辑集合e和正确编辑集合g;
2) 然后我们通过如下公式计算\(F_{0.5}\)指标:
\[P = \frac{TP}{TP + FP} = \frac{\lvert g \cap e \rvert}{\lvert e \rvert}\] \[P = \frac{TP}{TP + FN} = \frac{\lvert g \cap e \rvert}{\lvert g \rvert}\] \[F_{0.5} = \frac{(1 + {0.5}^2) \times R \times P}{R + {0.5}^2 \times P}\]其中,\(\lvert \rvert\)代表集合内的编辑数目,\(\cap\)代表两个编辑集合的交集。\(F_{0.5}\)代表更重视精确度,是目前中英文语法纠错最广泛使用的评估指标。
3) 如果当前句子有多种修改方式(假设 \(n\)种),那么我们对每个修改方式都抽取一个编辑集合,将预测编辑集合与所有正确编辑集合对比,选取尽可能大的\(F_{0.5}\)指标作为当前句子的指标。
3.4 赛道四:语法纠错质量评估
赛道四需要最终提供一个语法纠错质量评估结果,该结果可以由多个语法纠错质量评估模型整合得到。结果文件提交时要求参赛队伍对测试集生成的分数和纠错结果文件打包(zip/tar.gz)。压缩包内文件请严格命名为“correction_test.out”和“score_test.out”,方便我们后续处理。请参考Readme中的示例提交格式,并且严格保证每一行有且仅有一个改错结果或分数。评测分为两个方面:
1) 评价质量评估模型所生成的质量评估分数,具体而言是计算模型给出同一个输入文本的不同语法纠错结果的质量评估分数\((x)\)与真实\(F_{0.5}\)分数\((y)\)之间的皮尔逊相关系数(Pearson Correlation Coefficient,PCC),最后根据全部评测样例求取平均值用以衡量语法纠错质量评估分数与真实\(F_{0.5}\)分数之间的相关性。
\[r = \frac{\sum{(x_i - \bar{x})(y_i - \bar{y} )}}{\sqrt{\sum{(x_i - \bar{x})^2(y_i - \bar{y})^2}} }\]2) 所给定的语法纠错结果进行重新排序,并选取分数最高的语法纠错结果作为最终的语法纠错结果,用以评价质量评估模型在语法纠错任务上的效果,采用的评价指标和计算方式与赛道三相同。
4、评测赛程
报名截止时间:2022年5月31日
数据集开放时间:2022年6月1日
提交截止时间:2022年9月1日
结果公布时间:2022年9月15日
以上时间均为暂定,请关注 CCL 2022 官方网站。
5、奖项设置
由中国中文信息学会为本次评测获奖队伍提供荣誉证书。
参考文献
[1] 张宝林. 2013. 关于通用型汉语中介语语料库标注模式的再认识. 世界汉语教学, 01:128-140.
[2] Shamil Chollampatt and Hwee Tou Ng. 2018. Neuralquality estimation of grammatical error correction. In Proceedings of EMNLP,pages 2528–2539.
[3] Zhenghao Liu, Xiaoyuan Yi, Maosong Sun, Liner Yang,and Tat-Seng Chua. 2021. Neural quality estimation with multiple hypotheses forgrammatical error correction. In Proceedings of NAACL-HLT, pages 5441–5452.
[4] Wu Shih-Hung, Chao-Lin Liu, and Lung-Hao Lee. 2013.Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013. In Proceedings ofthe Seventh SIGHAN Workshop on Chinese Language Processing, pages 35–42.
[5] Yu Liang-Chih, Lung-Hao Lee, Yuen-Hsien Tseng, andHsin-Hsi Chen. 2014. Overview of SIGHAN 2014 Bake-off for Chinese SpellingCheck. In Proceedings of The Third CIPS-SIGHAN Joint Conference on ChineseLanguage Processing, pages 126–32.
[6] Tseng Yuen-Hsien, Lung-Hao Lee, Li-Ping Chang, andHsin-Hsi Chen. 2015. Introduction to SIGHAN 2015 Bake-off for Chinese SpellingCheck. In Proceedings of the Eighth SIGHAN Workshop on Chinese LanguageProcessing, pages 32–37.
[7] Wang Dingmin, Yan Song, Jing Li, Jialong Han, andHaisong Zhang. 2018. A Hybrid Approach to Automatic Corpus Generation forChinese Spelling Check. In Proceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing, pages 2517–27.
[8] Yuanyuan Zhao, Nan Jiang, Weiwei Sun, and XiaojunWan. 2018. Overview of the nlpcc 2018 shared task: Grammatical errorcorrection. In CCF International Conference on Natural Language Processing andChinese Computing (NLPCC), pages 439–445.
[9] Yingying Wang, Cunliang Kong, Liner Yang, YijunWang, Xiaorong Lu, Renfen Hu, Shan He, Zhenghao Liu, Yun Chen, Erhong Yang, andMaosong Sun.2021.YACLC:AChinese Learner Corpus with MultidimensionalAnnotation. arXiv preprint arXiv:2112.15043.
[10] Yue Zhang, Zhenghua Li, Zuyi Bao, Jiacheng Li, BoZhang, Chen Li, Fei Huang, and Min Zhang. 2022. MuCGEC: a Multi-ReferenceMulti-Source Evaluation Dataset for Chinese Grammatical Error Correction. InProceedings of NAACL-HLT.
[11] Gaoqi Rao, Erhong Yang, and Baolin Zhang. Overviewof NLPTEA-2020 Shared Task for Chinese Grammatical Error Diagnosis. In Proceedingsof the 6th Workshop on Natural Language Processing Techniques for EducationalApplications.
[12] 张宝林. 2009. “HSK动态作文语料库”的特色与功能. 汉语国际教育, 4:71–79.
[13] 张宝林,崔希亮. 2022. “全球汉语中介语语料库”的特点与功能. 世界汉语教学, 01:90-100.