成果 | 多语言开放式问答数据集OMGEval发布
背景
近一年,大模型发展迅速,带动了⼀系列通用人工智能技术的迅速发展,对大模型性能的评测随之涌现。
从评测能力上来看,由于目前的评测数据集主要是利用人类试题及其标准答案进行评测,这种评价方式更偏向对推理能力的评估,存在评估结果和模型真实能力有⼀定偏差。例如,英文数据集中,HELM1使用16个NLP数据集,MMLU2用57项⼈类考试科目来评测大模型。中文数据集中,GAOKAO3、C-Eval4等也采用人类试题,他们在自动化评测流程中都只包含有标准答案的问题,无法全面衡量生成式大模型的综合能力。
此外,目前也有一些工作关注到了模型的开放式问答,由斯坦福大学提出的的AlpacaEval被广泛认可,但仅由英文问题组成,决定了只能评估模型在英文上的表现。包含中文开放式问答的SuperCLUE数据集是首个提出开放式问答的中文数据集,但其数据集闭源,且也仅由中文问题组成。可以看到,目前已有的开放式问题数据集都是在单一语言上进行评测的,用来衡量模型的多语言能力的开源的开放式问答数据集仍然空缺。
综上所述,构建一个多语言的开放式问答数据集用以全面评测大模型的综合能力是有必要的。我们将从中文入手,逐渐迁移至其他语言。 ##介绍
多语言开放式问答数据集(OMGEval😮: An Open Multilingual Generative Evaluation Benchmark for Foundation Models)由北京语言大学、清华大学、东北大学、上海财经大学等高校组成的团队共同发布。主要项目参与人员有刘洋、朱琳、余婧思、徐萌、王誉杰、常鸿翔、袁佳欣、孔存良、安纪元、杨天麟、王硕、刘正皓、陈云、杨尔弘、刘洋、孙茂松等。
本数据集已在GitHub开源,网址为:https://github.com/blcuicall/OMGEval
数据集构建过程
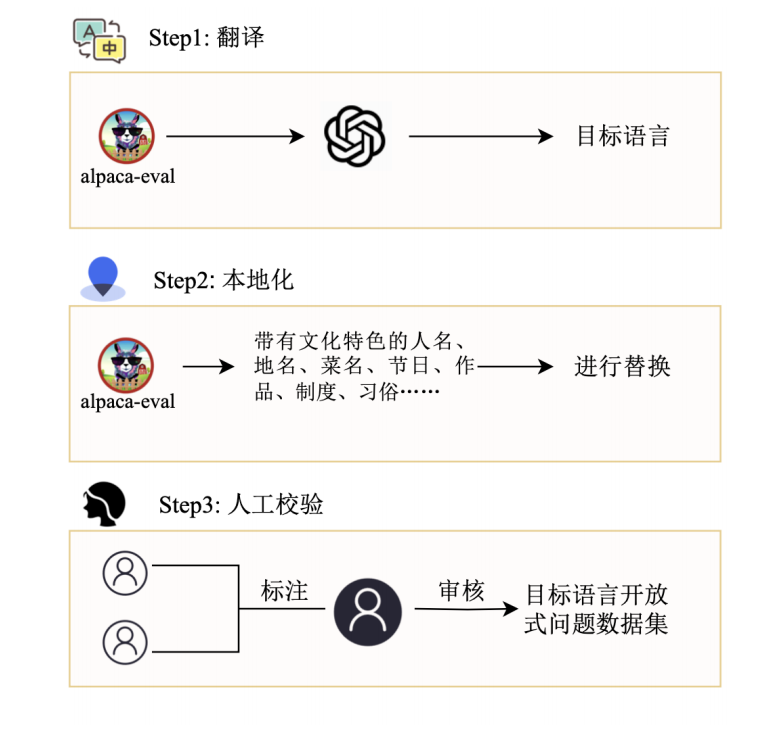
1.翻译
用ChatGPT将AlpacaEval中所有的句子翻译成中文。我们使用的prompt是:

2.本地化
对大模型语言能力的评测不仅仅体现在提问和作答的语言是中文,还有语言背后蕴含的文化信息。我们对AlpacaEval中包含文化元素的句子进行本地化,包括但不限于人物、电影书籍等作品、节日等。本地化的目的是使这些问题都更加契合中国文化。
以下是几个本地化的例子:

3.人工校验
对经过翻译和本地化的句子进行人工校验,每个句子由2名标注员,1名审核员校验,标注员和审核员均由语言学专业的硕士研究生担任。
数据集分析
我们最终得到一个包含804个中文问题的开放式问答数据集。
我们将模型能力划分为9个类别,分别如下

数据集在评估能力上的分布如下:
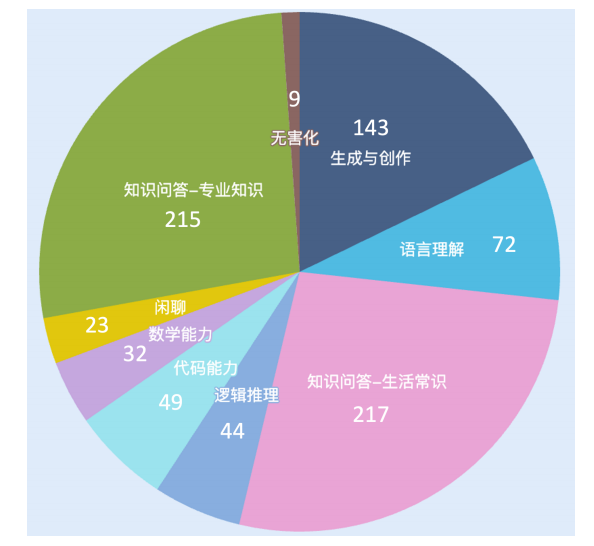
可以看到,目前的数据集中评估各项能力的题目数量分布还不是太均衡,后续我们会新增开放式题目使得数据均衡。
评估方法
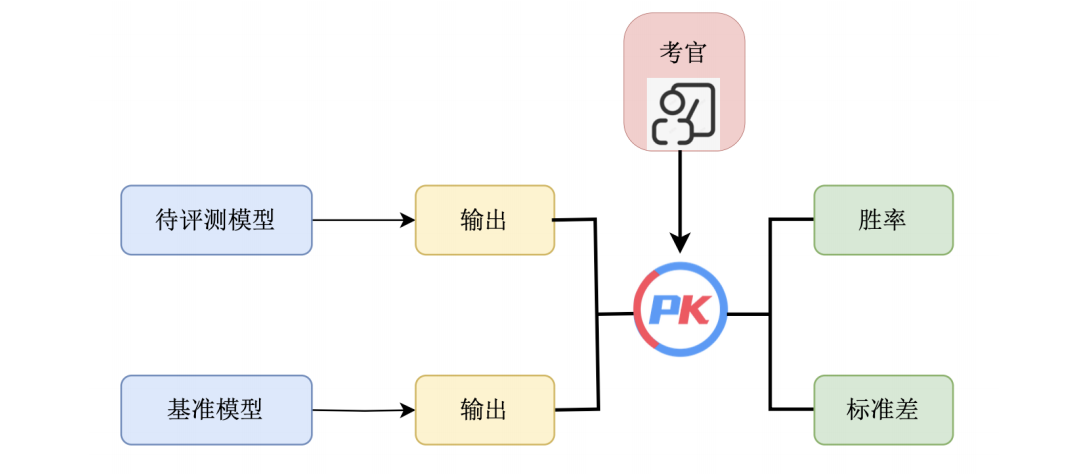
AlpacaEval 是斯坦福大学发布的用于自动评估大语言模型的排行榜,它包括了从测评数据集、模型回答生成,到自动评估的完整评测流程,目前榜单已经包含了来自全球各个机构的多个代表性模型。具体而言,该排行榜主要评估大模型遵从指令的能力以及回答质量,其中排行榜所使用的数据集共计 805 条指令,集成了来自于 Self-instruct,Open Assistant, Vicuna 等项目发布的测评数据。如上图所示,排行榜的具体指标计算方式为使用一个大模型作为考官(通常为GPT-4),自动评估当前模型的回答与选取的基准模型(通常为Text-Davinci-003) 的回答,统计当前模型的胜率。
AlpacaEval 的实验表明,榜单所采用的 GPT-4 评估与人类标注结果的皮尔逊相关系数达到 94%,说明该评估方式可靠性较高。同时,研究人员对评估的成本也做了一定的分析,说明了当前评估方式大幅降低了人工评估所花费的经济成本和时间成本。
参考AlpacaEval 的评估方法,我们同样采用Text-Davinci-003的输出作为基准,采用GPT-4作为评估器,为待评估模型和基准输出哪个更优做出判断,计算胜率和标准差。具体来看,为了保证模型对OMGEval数据集中的问题的输出都为中文,我们在prompt中使用中文提问,此外,我们对GPT-4评估模型输出的prompt也做了相应修改,如下:

评估榜单
根据上述评估方法,采用Text-Davinci-003的输出作为基准,采用GPT-4作为评估器,我们得到以下榜单:
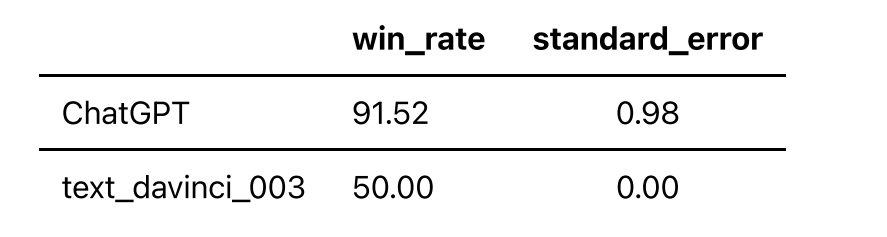
可以看到,ChatGPT在本地化的问题集上得分低于在问题全集上的得分。 更多模型仍在评测中🚧,敬请期待。
参考文献
[1] Liang P, Bommasani R, Lee T, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022.
[2] Hendrycks D, Burns C, Basart S, et al. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
[3] Zhang X, Li C, Zong Y, et al. Evaluating the Performance of Large Language Models on GAOKAO Benchmark. arXiv preprint arXiv:2305.12474, 2023.
[4] Huang Y, Bai Y, Zhu Z, et al. C-eval: A multi-level multi-discipline Chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
[5] Dubois Y, Li X, Taori R, et al. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387, 2023.
[6] Xu L, Li A, Zhu L, et al. SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark. arXiv preprint arXiv:2307.15020, 2023.