满血版DeepSeek-R1 671B模型私有化部署指南
自2025年初发布以来,DeepSeek-R1 671B模型凭借其媲美人类专家的推理能力及免费开源的特性,迅速成为全球AI领域的焦点,并被广泛应用于课程教学、学术研究、办公辅助、智能决策等场景。
对高校而言,数据隐私与业务连续性至关重要。传统云端模型依赖外部服务器,存在数据泄露风险与网络延迟瓶颈,而私有化部署DeepSeek-R1除了可以实现数据安全的“护城河”,还能够基于知识库根据需要完成深度定制化。
尽管蒸馏版DeepSeek(如8B、70B)降低了硬件门槛,但其本质是基于Llama或Qwen的精简模型,牺牲了原版的深度思考推理能力与复杂任务泛化性。相比之下,未经蒸馏和量化的Deepseek-R1 671B模型则拥有更加强大的思考和推理能力。
DeepSeek-R1 671B模型的终极价值,在于与检索增强生成(RAG)技术的结合。通过本地部署的向量数据库与嵌入模型(如bge-m3),高校和学院可将私有的内部文档、相关资料等转化为大语言模型的知识,构建私有知识库,实现高效生成、精准问答、智能决策。
本文介绍了如何使用两台H20 (96G)服务器部署满血版DeepSeek-R1 671B模型。
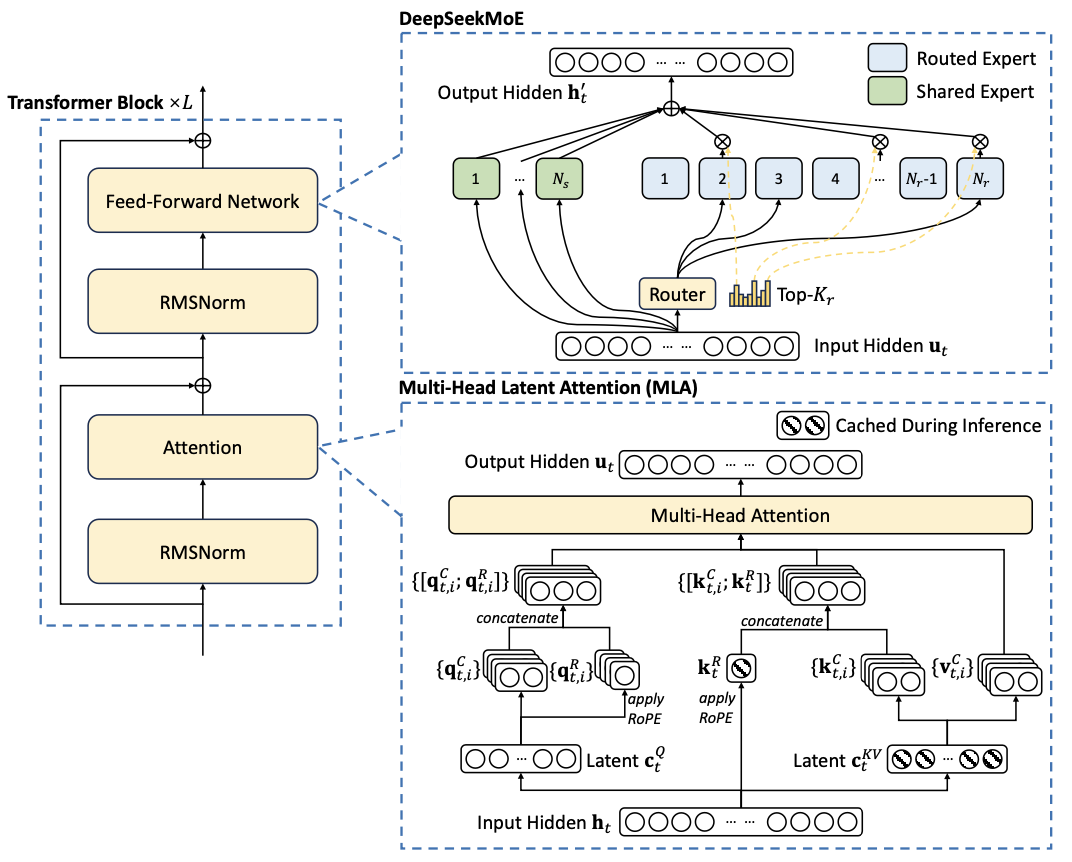
图1 DeepSeek创新技术架构
检索增强生成原理

图2 检索增强生成原理
应用部署架构
部署方案采用两台H20 (96G)节点构建RAY集群,基于vLLM部署支持高并发的DeepSeek-R1模型。基于Ollama部署bge-m3模型作为嵌入模型,使用AnythingLLM实现检索增强生成并搭建用户界面。
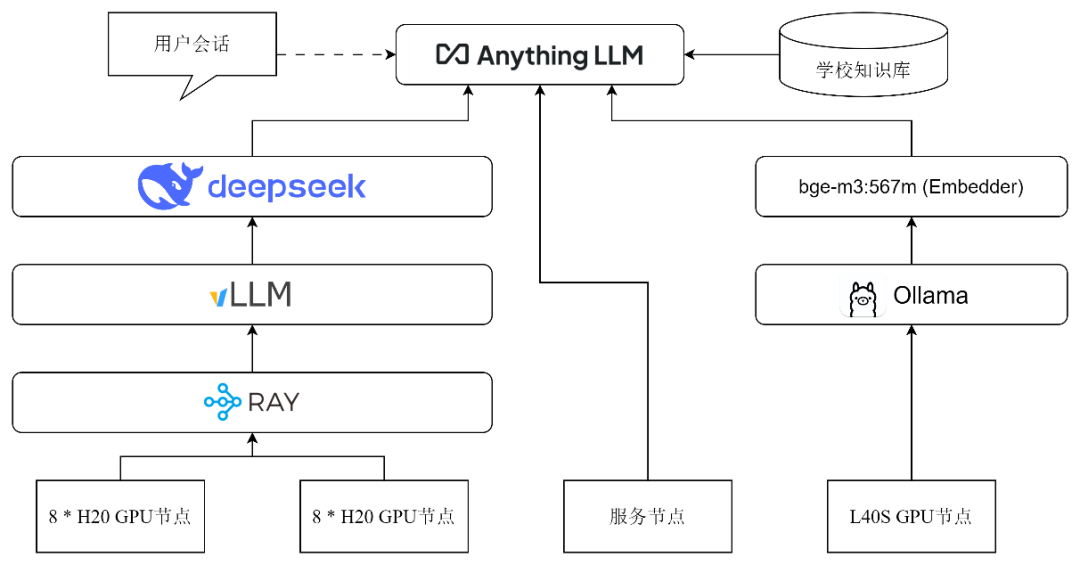
图3 应用部署架构
部署过程指令
1.安装Miniconda并创建虚拟环境,建议使用conda创建隔离环境并管理所需依赖。

2.安装RAY集群 由于vLLM的分布式计算依赖于RAY集群,因此可以参照官方文档进行安装。

3.启动RAY集群并查看状态 RAY集群安装成功后,即可使用“ray start”指令启动集群Head节点,并按照其提示将Worker节点加入集群。集群成功启动后,可以使用“ray status”查看集群状态,或访问Head节点的8265端口可视化查看资源使用情况等。

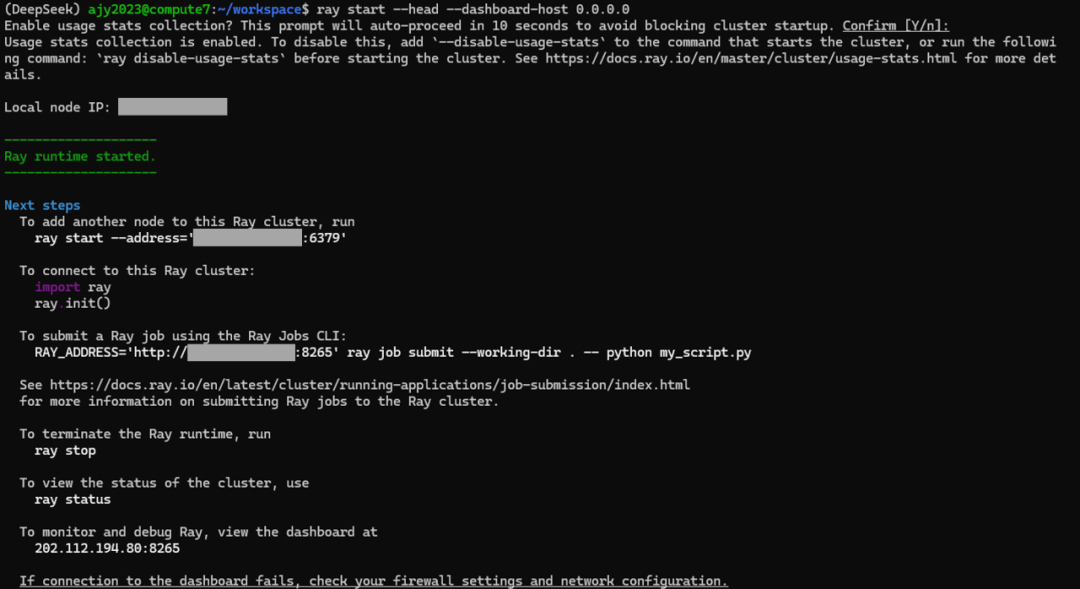
图4 Head节点启动与其输出

图5 Worer节点启动与其输出
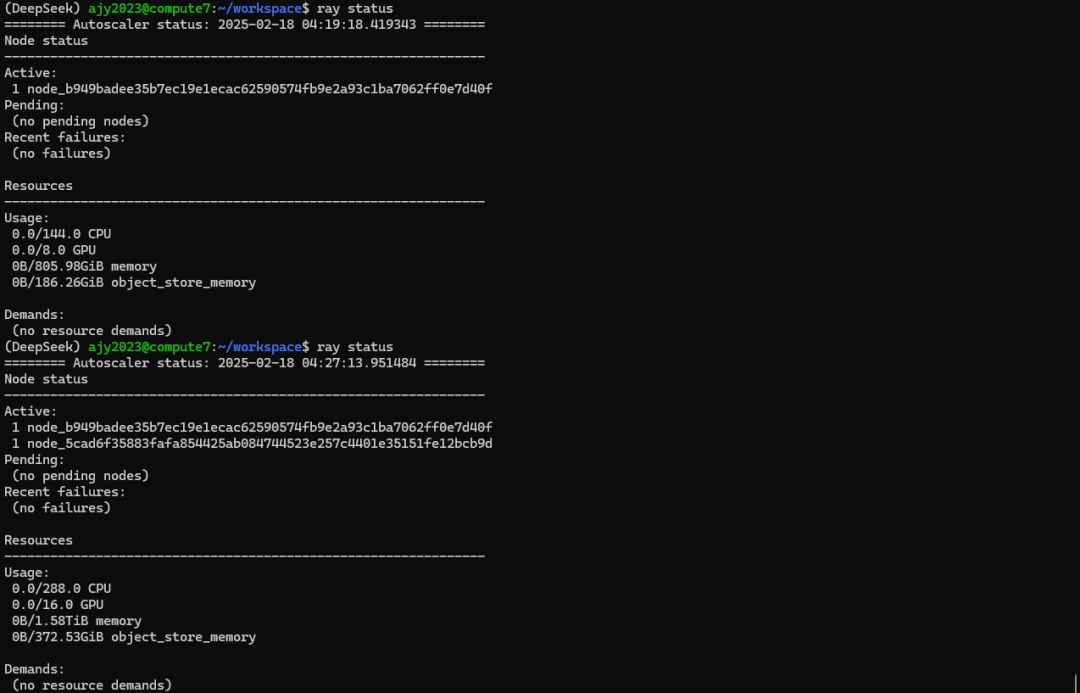
图6 加入Worker节点前后集群状态变化
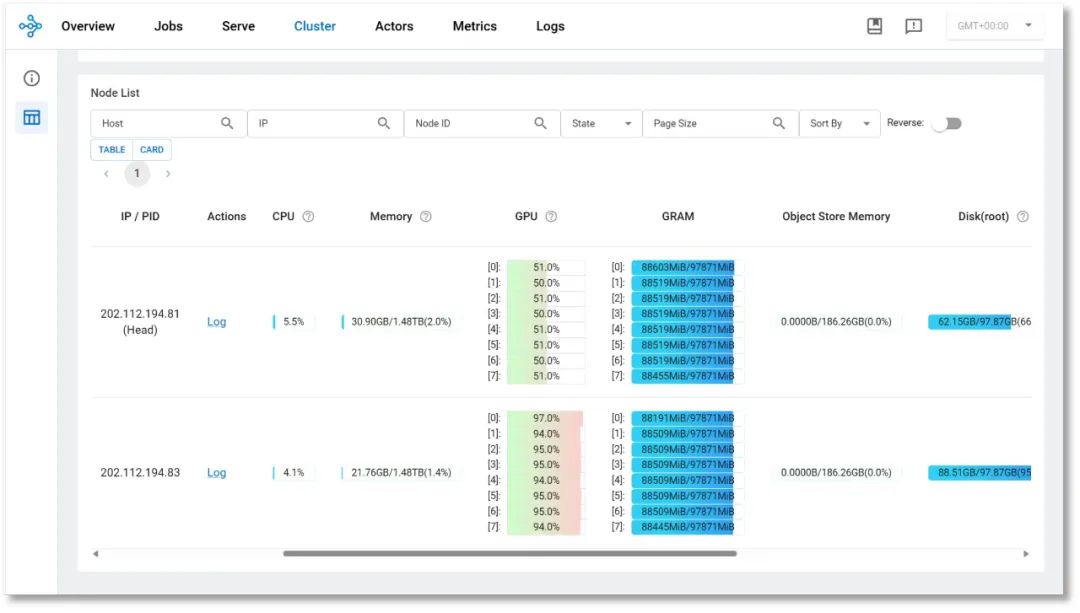
图7 集群状态监控页面
4.使用魔搭社区下载模型权重文件 由于国内使用HuggingFace下载较慢,推荐使用魔搭社区的模型镜像下载模型权重文件等。使用“–local_dir”参数可以指定下载的路径。

5.安装并启动vLLM 使用 “vllm serve”启动vLLM服务,默认端口为8000。

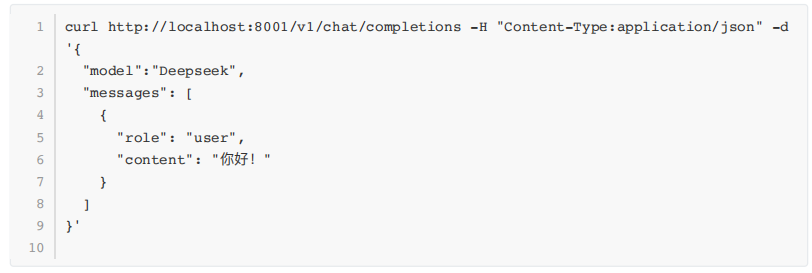
6.验证vLLM API是否可用 可以在命令行中使用curl指令或使用OpenAI Python库访问已部署的vLLM DeepSeek服务
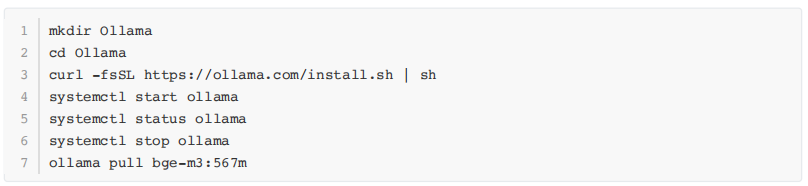
7.安装Ollama与Embedder模型 由于AnythingLLM内置的Embedder模型效果不佳,建议使用基于Ollama部署对于中文支持较好的“bge-m3:567m”嵌入模型。